В мире программного обеспечения производительность играет ключевую роль. Она влияет на пользовательский опыт, уровень удовлетворенности клиентов и даже на общую рентабельность бизнеса. Особенно это актуально для PHP-приложений, которые славятся своей простотой и гибкостью, но при этом могут столкнуться с проблемами производительности при неоптимальном использовании.
В этой статье мы погрузимся в мир оптимизации PHP-приложений. Мы рассмотрим, как вы можете улучшить производительность своего кода, не угрожая его читаемости или функциональности. Мы обсудим различные стратегии и подходы, начиная от элементарных лучших практик, таких как аутсорсинг вычислений и кэширование, и заканчивая более сложными темами, такими как микрооптимизация и оптимизация последовательности.
Однако прежде чем мы начнем, стоит напомнить, что оптимизация - это не всегда панацея. Важно оставаться реалистами и понимать, что не все улучшения производительности могут оказать заметное влияние на общую эффективность вашего приложения. Следовательно, лучше всего сосредоточиться на тех участках кода, которые действительно могут принести заметные результаты.
Когда думаешь о надёжном программном обеспечении, первое, что приходит на ум, - это использование эффективного кода. С помощью оптимизаций мы создаем алгоритмы, которые выполняют ту же задачу с существенно меньшими расходами. Эта мысль в некотором смысле является основой качественного программирования.
Мы уже не можем представить себе повседневную жизнь без программного обеспечения, и мы не хотим этого менять. Однако мы должны стараться использовать как можно меньше ресурсов для получения того же результата.
Алгоритмы - основа в базовой подготовке разработчиков программного обеспечения. Но, положа руку на сердце - как часто вы всё же пишете самостоятельно, например, функцию сортировки? Вот именно, почти никогда. Гораздо чаще мы опираемся на существующие функции, которые предлагает нам PHP. Это разумно, поскольку эти функции проверены и отработаны, и написать более быстрые функции мы, как правило, не сможем.
Но даже если мы обычно не пишем такие специализированные алгоритмы сами, всё равно существует масса других ошибок, которые иногда могут существенно повлиять на производительность. Особенно если речь идет об огромных циклах, то даже небольшие потери производительности могут сильно сказаться на работе системы.
К сожалению, то и дело выясняется, что даже элементарные лучшие практики не применяются:
- Аутсорсинг вычислений: есть ли операции, которые не требуются выполнять при каждом проходе цикла? Если да, то выполните операцию один раз и сохраните результат в переменной.
- Кэширование: не всегда это должен быть Redis, даже простое кэширование in-memory с помощью массива может быть очень полезным, чтобы избежать повторных запросов к базе данных и т.п.
- Разумная микрооптимизация: Такие улучшения производительности, как использование одинарных кавычек вместо двойных, оказывают лишь незначительное влияние на производительность, но в критических по производительности частях кода они могут иметь небольшое значение. Хороший обзор можно найти, например, в The PHP Benchmark.
- Оптимизация последовательности: Даже небольшие изменения в потоке программы могут увеличить скорость работы, например, за счёт расположения условий в if-запросах в зависимости от скорости выполнения. Условия, не требующие больших затрат вычислительного времени, должны проверяться в первую очередь.
При всей любви к оптимизации: оставайтесь реалистами! Если вы потратите несколько часов на минимальное улучшение скрипта, который редко запускается, то вряд ли бизнес заработает на этом достаточно денег.
В соответствии с известным высказыванием Дональда Кнута "Преждевременная оптимизация - корень всех зол", лучше сначала позаботиться о тех участках кода, которые оказывают заметное влияние на производительность.
Базы данных
Реляционные базы данных также являются распространенным источником производительности приложений. Справиться с этим можно с помощью следующих основных правил:
- Оптимизируйте таблицы: Об индексах, в частности, часто забывают, поскольку их отсутствие замечают только при больших объемах данных, как это происходит в крупных системах, из-за падения производительности.
- Экономия данных: не запрашивайте ненужные данные, т.е. избегайте SELECT *, если требуется всего несколько столбцов, и обращайте внимание на разумные инструкции LIMIT.
- Используйте альтернативы: Реляционные базы - не лучший выбор для хранения больших объемов неструктурированных данных (например, журналов), поскольку доступ на запись в них дорог и его следует избегать. Используйте для этого альтернативы NoSQL, которые справляются с этой задачей гораздо лучше.
Благодаря объектно-ориентированному программированию (ООП), абстракциям баз данных (DBAL) и объектно-реляционному отображению (ORM) многие запросы спрятаны глубоко под слоями кода, толщина которых достигает нескольких метров, и их трудно понять. Особенно, если речь идет о запросах, созданных с помощью таких инструментов, как Eloquent или Doctrine. Здесь следует проявлять большую осторожность, так как в противном случае получается, что одинаковые запросы выполняются по нескольку раз на один поток.
Поэтому следует взять за привычку протоколировать все запросы к базе данных на локальной системе разработки, а также регулярно просматривать эти журналы. Такие инструменты, как PHP Debug Bar, легко интегрируются в существующие приложения и показывают, сколько запросов отправляется на одно открытие страницы или как быстро они выполняются. Для выявления особенно медленных запросов можно также воспользоваться инструментом журналирования. Ознакомьтесь с оператором EXPLAIN для поиска недостающих индексов.
Здесь, конечно, большую роль играет удобство. Удобно одним вызовом получить массив или коллекцию готовых инициализированных объектов. В конце концов, мы используем ООП, а все остальные способы - это каменный век, не так ли? Но люди не обращают внимания на то, что даже самая лучшая ORM имеет накладные расходы, а библиотеки-конструкторы иногда выдают низкопроизводительные запросы.
Очень плохо, когда результат запроса содержит много записей, потому что тогда для каждой строчки инстанцируется отдельный объект. Если нам приходится выполнять итерации над тысячами объектов, то не стоит удивляться, что выполнение запроса занимает больше времени.
Для больших объемов данных непосредственное использование SQL-запросов, например, через PDO, часто является более рациональным выбором. Нет ничего зазорного в использовании хорошо продуманных SQL-запросов и простых массивов, если мы аккуратно инкапсулируем это, например, в репозиторий. От повышения производительности выигрывает не только система, но и пользователи.
Выявление узких мест
Оптимизация имеет смысл только в том случае, если мы не просто уходим в бесконечность, а производим измерения и сравниваем результаты. Для этого даже не нужны специальные инструменты. Например, если мы хотим узнать, что лучше - str_contains или preg_match - для поиска подстроки, то это можно быстро выяснить самостоятельно:
<?php
declare(strict_types=1);
namespace App\Console\Commands;
use Illuminate\Console\Command;
final class CompareStringsCommand extends Command
{
protected $signature = 'compare:strings';
protected $description = 'Comparing performance of different commands';
public function handle(): int
{
$start = microtime(true);
for ($i = 0; $i <= 200000; $i++) {
str_contains('Is there are any word Sergey here?', 'Sergey');
}
$end = microtime(true);
$this->info( "result of str_contains(): ". sprintf('%.4f', $end - $start). "\n");
$start = microtime(true);
for ($i = 0; $i <= 200000; $i++) {
preg_match("/php/i", 'Is there are any word Sergey here?');
}
$end = microtime(true);
$this->info( "result of preg_match(): ". sprintf('%.4f', $end - $start). "\n");
return 1;
}
}
Вышеуказанная команда в Laravel запускается через php artisan compare:strings и даёт нам следующий результат:
result of str_contains(): 0.0042
result of preg_match(): 0.0089
Абсолютные числа здесь не имеют значения, но в соотношении становится очевидно, что в данном конкретном случае str_contains явно быстрее. Это неудивительно, поскольку preg_match слишком сложен для решения этой простой задачи. Но это также показывает, что выбор средств должен быть хорошо продуман. Единичный вызов может и не иметь значения, но в больших количествах - имеет.
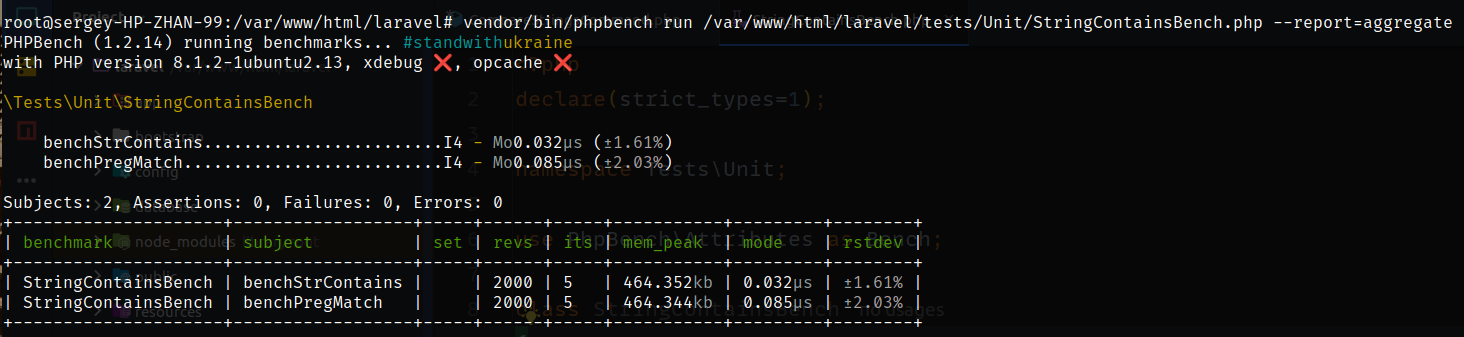
Кстати, как показывает рисунок к посту, сравнение производительности с помощью инструмента PHPBench даёт нам более наглядные и точные показатели. Тестовый класс имеет очень простую структуру
<?php
declare(strict_types=1);
namespace Tests\Unit;
use PhpBench\Attributes as Bench;
class StringContainsBench
{
#[Bench\Revs(2000)]
#[Bench\Iterations(5)]
public function benchStrContains(): void
{
str_contains('Is there Sergey string here?', 'Sergey');
}
#[Bench\Revs(2000)]
#[Bench\Iterations(5)]
public function benchPregMatch(): void
{
preg_match("/Sergey/i", 'Is there Sergey string here?');
}
}
Атрибуты #[Bench\Revs] и #[Bench\Iterations] определяют, как часто следует повторять измерения, чтобы избежать помех в оценке. За более подробной информацией обращайтесь к документации проекта. Измерение производительности таких небольших участков кода имеет смысл только в том случае, если мы примерно представляем, какие участки могут быть проблемными. Для их поиска полезными инструментами являются отладчики и профилировщики.
Пожалуй, самым известным отладчиком в мире PHP является Xdebug. С его помощью мы можем выполнять программу построчно. Собственно, инструмент и используется для отладки, но при пошаговом выполнении нашего кода, пошаговой отладке, мы уже получаем первое представление о том, какие участки кода работают особенно медленно.
Ещё более точный анализ можно провести с помощью профилировщика. Он фиксирует каждый вызов функции при выполнении программы с указанием его длительности и таким образом может создать подробную картину внутренней работы. Может быть, медленная функция вызывается особенно часто, или где-то есть цикл, о котором вы даже не подумали?
Кстати, Xdebug поставляется вместе с профилировщиком. Если он активирован, то для каждого запуска создаётся файл в формате cachegrind. Однако для его считывания необходим другой инструмент. Если ваша IDE не поддерживает этот формат, то существуют такие инструменты, как KCacheGrind или QCacheGrind.
Под полной нагрузкой
В локальном режиме разработки для тестирования обычно используются только небольшие наборы данных. Таким образом многие узкие места остаются невыявленными до тех пор, пока их не обнаружат заказчики, которые, например, хотят импортировать уже не несколько десятков, а сотни тысяч строк CSV-данных. Коммерческие инструменты, такие как NewRelic, Blackfire или Tideways, измеряют производительность сложных систем и вникают в мельчайшие детали. Они могут дать ценную подсказку о том, где именно возникают проблемы.
Однако эти инструменты стоят недешево, поэтому ими часто пренебрегают. Когда заказчики сталкиваются с реальными проблемами в производительности, их начинают лихорадочно закупать. Но они были бы гораздо полезнее, если бы с самого начала были встроены в систему.
Толстые библиотеки
Пакеты следует выбирать с осторожностью, поскольку они, как правило, страдают "фичуритом": впитав за годы работы бесчисленное количество фичей, они часто перегружаются функциями - и, соответственно, становятся слишком тяжелыми.
В качестве примера можно привести широко распространенный Nesbot/Carbon. Само название, конечно, очень подходит по тематике, но оно также наглядно показывает, как лучше не делать. Carbon претендует на то, чтобы предоставить простой API для собственных функций даты в PHP. Возможно, это тоже вопрос личного вкуса. Мы не хотим спорить о вкусах, но мы говорим о производительности - и здесь Carbon работает значительно хуже, как показывает код ниже, опять же с помощью PHPBench.
<?php
declare(strict_types=1);
namespace Tests\Unit;
use Illuminate\Support\Carbon;
use PhpBench\Attributes as Bench;
class CarbonDateBench
{
#[Bench\Revs(2000)]
#[Bench\Iterations(5)]
public function benchStrtotime(): void
{
strtotime('-30 days');
}
#[Bench\Revs(2000)]
#[Bench\Iterations(5)]
public function benchCarbon(): void
{
Carbon::now()->subDays(30)->getTimestamp();
}
#[Bench\Revs(1000)]
#[Bench\Iterations(5)]
public function benchDateTime(): void
{
(new \DateTime('-30 days'))->getTimestamp();
}
}
Здесь для определения временной метки даты 30 дней назад мы используем три различных способа: функцию strtotime, объект DateTime (оба - PHP-родные) и Carbon. Как видно из результата работы, для решения той же задачи за 8 микросекунд Carbon требуется в 16 раз больше времени выполнения, чем двум альтернативным вариантам за 0,5 микросекунды каждый.
root@sergey-HP-ZHAN-99:/var/www/html/laravel# vendor/bin/phpbench run /var/www/html/laravel/tests/Unit/CarbonDateBench.php --report=aggregate
PHPBench (1.2.14) running benchmarks... #standwithukraine
with configuration file: /var/www/html/laravel/phpbench.json
with PHP version 8.1.2-1ubuntu2.13, xdebug ❌, opcache ❌
\Tests\Unit\CarbonDateBench
benchStrtotime..........................I4 - Mo3.240μs (±1.28%)
benchCarbon.............................I4 - Mo11.327μs (±1.32%)
benchDateTime...........................I4 - Mo4.297μs (±2.04%)
Subjects: 3, Assertions: 0, Failures: 0, Errors: 0
+-----------------+----------------+-----+------+-----+----------+----------+--------+
| benchmark | subject | set | revs | its | mem_peak | mode | rstdev |
+-----------------+----------------+-----+------+-----+----------+----------+--------+
| CarbonDateBench | benchStrtotime | | 2000 | 5 | 4.948mb | 3.240μs | ±1.28% |
| CarbonDateBench | benchCarbon | | 2000 | 5 | 5.409mb | 11.327μs | ±1.32% |
| CarbonDateBench | benchDateTime | | 1000 | 5 | 4.948mb | 4.297μs | ±2.04% |
+-----------------+----------------+-----+------+-----+----------+----------+--------+
Опять же, единичные вызовы не вызывают проблем, но при массовом выполнении это, безусловно, имеет значение. Да и зачем вообще использовать значительно более медленную функцию, если альтернативы не хуже?
Но все становится еще хуже. Carbon занимает почти 5 Мбайт памяти. Во многом это связано со 180 языковыми файлами в каталоге Lang, которые в сумме занимают 3,5 Мбайт. Как правило, в приложении поддерживаются не все языки мира, так что, по самым скромным подсчетам, для нашего проекта может понадобиться всего 500 килобайт языковых файлов. Оставшиеся три мегабайта неиспользуемых языковых файлов в любом случае входят в состав каждой инсталляции.
Кажется, что три мегабайта - это не так уж и много. Однако, если учесть, что в настоящее время ежедневно устанавливается около 200 тыс. программ Carbon, то это вызывает более 200 терабайт ненужного сетевого трафика в год. Поэтому в данном случае имеет смысл передать языковые файлы на аутсорсинг, чтобы они загружались только при необходимости. Кстати, из аналогичных соображений был сделан известный пакет fzaninotto/Faker, который не получил дальнейшего развития от первоначального разработчика.
Всегда могут возникнуть ситуации, когда использование карбона необходимо для решения конкретной задачи. Однако по возможности следует стараться обходиться без него. Например, собственные функции даты в PHP часто оказываются вполне адекватными и гораздо более быстрыми, но, возможно, не столь удобными в использовании.
Возможно, существует более компактная альтернатива пакету? Например, Guzzle - тоже очень часто используемый пакет. Для сравнения, Nyholm/PSR7, например, имеет гораздо меньше кода и обеспечивает более высокую скорость работы при аналогичном наборе функций.
Что же нужно сделать в первую очередь?
В этой статье невозможно перечислить все способы повышения производительности приложений, но я все же хочу бы дать вам пищу для размышлений:
- Бережливые API: отправляйте в ответ только самые необходимые данные. API GraphQL, естественно, имеют здесь преимущество в силу своего принципа, но данные можно экономить и в RESTful API, предоставляя дополнительные конечные точки для особых случаев, когда требуется больше данных. Можно также предоставить клиентам возможность самим решать, какие данные должны быть включены в ответ, с помощью специальных параметров запроса. Например, вызов
GET /user?fields=id,last_name,first_name будет предписывать эндпоинту user предоставлять только поля id, last_name и first_name. На стороне сервера это, конечно, должно быть реализовано.
- Сжатие: gzip-сжатие для веб-сайтов или API позволяет экономить пропускную способность и тем самым повышает производительность. Звучит банально, но об этом часто забывают.
- Сборка процессов: Не забывайте использовать кэширование для конвейеров CI/CD, особенно для Composer. Это экономит много ценного вычислительного времени.
- Docker: контейнеры часто таскают с собой ненужные данные. Контейнеры на базе экономичного Alpine Linux в несколько раз меньше, а значит, собираются быстрее.
- Composer: Удаление ненужных пакетов composer, которые в противном случае устанавливаются снова и снова при каждой сборке или обновлении composer. В этом могут помочь такие инструменты, как composer-unused.
Зачем все это нужно?
К сожалению, к теме производительности часто относятся как к второстепенной. Тем не менее, нельзя недооценивать влияние производительности на затраты, удовлетворенность клиентов и прибыль бизнеса. Ранний мониторинг производительности может предотвратить худшие последствия. Но как только код попадает на прод, рефакторинг становится не таким уж простым делом. Хуже всего, наверное, объяснять менеджеру по продукту, почему для того, чтобы сделать уже готовую, протестированную и утвержденную функциональность пригодной для использования под нагрузкой, требуется еще один спринт.
За свою карьеру я сталкивался с бесчисленным количеством примеров, когда даже небольшие улучшения быстро приводили к более чем десятикратному ускорению кода.
Особенно в облаке эти проблемы с производительностью могут стать еще и дорогостоящими. При использовании автомасштабирования, т.е. автоматической адаптации предоставляемых ресурсов к текущей нагрузке, эти узкие места быстро компенсируются за счет увеличения вычислительной мощности и поначалу остаются незамеченными, по крайней мере, до тех пор, пока кто-то не присмотрится к вычислениям. Таким образом, при хорошей производительности программное обеспечение может быть выгодно и с финансовой точки зрения.
В заключение
Оптимизация производительности - это сложный процесс, который требует глубокого понимания как конкретного приложения, так и общих принципов программирования и работы систем. Однако результаты этого процесса могут быть весьма впечатляющими. Меньшее использование ресурсов, быстрое выполнение задач, улучшенный пользовательский опыт - всё это лежит в зоне доступа тех, кто готов потратить время и усилия на оптимизацию своего кода.