В работе любой программист или системный администратор встречается со страшной проблемой — тормозит база. Сервер работает медленно, происходит нечто непонятное, пользователи жалуются, клиент ругается. Я не зря написал, что проблема является страшной, в первую очередь потому, что решение здесь будет неочевидное и лежит оно не на поверхности. На производительность базы может влиять множество параметров.
В этой статье я постарался рассмотреть большинство из них, а также перечислю те команды, которые помогают мне понять причины медленной работы сервера или базы данных.
Ниже перечислю этапы, по которым вам следует пройтись, чтобы понять причины проблемы.
1. Смотрим, что было сделано раньше.
Для этого у вашего приложения должен быть Git. Заходим в него и смотрим, что было сделано ранее. Какие вы делали миграции, какие настройки меняли.
И желательно, чтобы основной файл конфигурации БД postgresql.conf также был в гите. Тогда вы сможете в том числе контролировать и изменение настроек базы.
Конечно, вы должны взять за правило — не делать никаких изменений в базе напрямую, а всё проводить через гит и миграции.
Особенно если речь идёт об изменениях структуры базы данных, добавлении обработчиков, пользовательских функций, процедур. Эти работы должны делать скрипты, которые, в свою очередь, должны версионироваться.
2. Смотрим, что происходит в операционной системе.
Если изменений в гите не было, а проблема возникла неожиданно, то следующее, на что стоит обратить внимание — что происходило в операционной системе.
Надеюсь, база данных у вас установлена на Linux-машине. Если нет, то советую подумать о переезде на Linux.
Вспомните, какие антивирусы или сетевые экраны вы устанавливали. Посмотрите, какие приложения или сервисы подняты на сервере, кроме базы данных. Оптимальный подход — держать на сервере только базу данных и ничего лишнего. Благо, текущие технологии по виртуализации позволяют это сделать очень быстро и просто.
3. Проверяем оборудование.
Опять же, если в операционной системе вы ничего не меняли, у вас уже стоит Linux, стоит обратить внимание на оборудование. Сегодня некоторые производители железа грешат качеством и нельзя надеяться на то, что память или жёсткий диск не выйдут из строя в самый неподходящий момент. Поэтому, первое на что советую обратить внимание:
htop
Если вы видите, что процессор загружен на 70% и более и при этом загружены все ядра, то подумайте об увеличении мощности. Процессоры сейчас дешёвые, а если вы используете виртуализацию, то добавьте вашей базе дополнительное количество ядер. Скорее всего, вашей базе перестало хватать мощностей из-за возросшей нагрузки и стоит подумать о модернизации сервера.
iostat –dx
Обратите внимание на последнюю колонку. Она вам даст представление о загрузке дисковой подсистемы. Если показатель приближается к 100%, то нужно подумать об увеличении памяти. Скорее всего, у вас очень большой размер базы данных, а оперативки на сервере для обработки данных слишком мало.
Помните, что расходы по оптимизации запросов или кода приложения не окупятся, если у вас присутствуют проблемы с оборудованием.
4. Установите систему мониторинга.
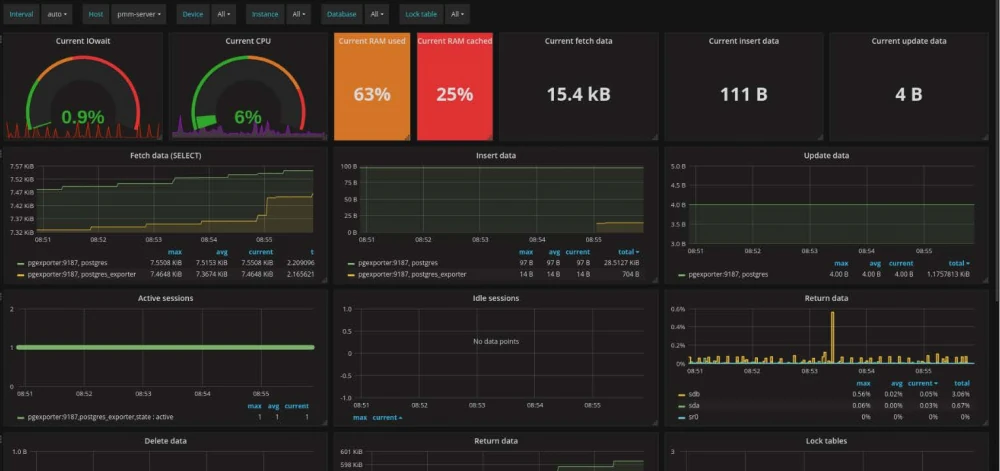
Попробуйте установить систему мониторинга Percona https://www.percona.com/software/database-tools/percona-monitoring-and-management. Её интерфейс показан на картинке выше. Она бесплатная и позволит вам быстро оценить динамику нагрузки на сервер и покажет все главные показатели работы сервера.
5. Проанализируйте файловое хранилище.
Запустите команду:
iostat –x
Посмотрите на колонки с постфиксов _await. Они говорят вам о показателе f/s latency. Если показатель больше 50 мс без нагрузки, то стоит задуматься. Если более 100 - то стоить предпринимать срочные меры.
Причиной высоких цифр может быть неверная настройка гипервизора или работа базы через NAS. Последнего подхода в проектировании нужно избегать.
6. Анализируем pg_stat_activity.
Итак, мы проверили сервера, оборудование, ничего необычного не нашли. Переходим непосредственно к тюнингу базы.
Первое, что приходит на ум — представление pg_stat_activity.
Сначала проверьте в настройках базы параметр track_activity_query_size, по умолчанию он выставлен на 1024. Увеличьте его как минимум в 2-3 раза, в большинстве случаев его не хватает.
Теперь ищем, какая активность у нас происходит в базе. Может всё гораздо проще и кто-то запустил сложный запрос и вам стоит остановить этот скрипт. Смотрим активные запросы длительностью более 5 секунд:
SELECT now() - query_start as "runtime", usename, datname, wait_event, state, query FROM pg_stat_activity WHERE now() - query_start > '5 seconds'::interval and state='active' ORDER BY runtime DESC;
Также могут вызвать подозрения запросы с состоянием "idle". А ещё хуже с состоянием "idle in transaction".
Такие запросы можно остановить следующими командами:
SELECT pg_cancel_backend(procpid);
SELECT pg_terminate_backend(procpid);
Первый остановит активные запросы, второй с типом idle.
Теперь стоит посмотреть, есть ли у вас зависшие трансакции. Выполняем запрос:
SELECT pid, xact_start, now() - xact_start AS duration FROM pg_stat_activity WHERE state LIKE '%transaction%' ORDER BY 3 DESC;
Помните, трансакции должны выполняться моментально. Из ответа смотрите на duration. Если трансакция висит несколько минут, а тем более часов, значит, приложение повело себя некорректно, оставив трансакцию незавершённой. А это влияет на репликацию, на работу VACUUM, WAL.
7. Анализируем pg_stat_statements.
Если раньше мы проверяли активные запросы, то теперь самое время проанализировать то, что было раньше. В этом нам поможет представление pg_stat_statements. Но обычно по умолчанию оно отключено, нам следует его активировать. Для этого в конфиге базы вставляем следующую строчку:
shared_preload_libraries = 'pg_stat_statements'
Затем в текущем сеансе работы с базой, запускаем команду:
create extension pg_stat_statements;
Если вы планируете заниматься производительностью базы, то оно вам нужно обязательно. Без него вы не сможете сделать многих вещей. Оно, конечно, займёт немного места на диске, но по сравнению с преимуществами это будет не страшно.
С помощью него вы можете получить статистику по уже выполненным запросам.
Например, мы можем получить запросы с максимальной загрузкой процессора такой командой:
SELECT substring(query, 1, 50) AS short_query, round(total_time::numeric, 2) AS
total_time, calls, rows, round(total_time::numeric / calls, 2) AS avg_time, round((100 *
total_time / sum(total_time::numeric) OVER ())::numeric, 2) AS percentage_cpu FROM
pg_stat_statements ORDER BY total_time DESC LIMIT 20;
А максимально долгие запросы - вот такой:
SELECT substring(query, 1, 100) AS short_query, round(total_time::numeric, 2) AS
total_time, calls, rows, round(total_time::numeric / calls, 2) AS avg_time, round((100 *
total_time / sum(total_time::numeric) OVER ())::numeric, 2) AS percentage_cpu FROM
pg_stat_statements ORDER BY avg_time DESC LIMIT 20;
Таким образом, мы можем понять, какие запросы сильно влияют на нагрузку нашей базы данных и оптимизировать их при необходимости.
8. Работаем с представлением pg_stat_user_tables
Таблица pg_stat_user_tables - ключевое конкурентное преимущество по сравнению с другими БД. С помощью неё мы, например, получить информацию о последовательном чтении с диска:
SELECT schemaname, relname, seq_scan, seq_tup_read, seq_tup_read / seq_scan AS avg, idx_scan
FROM pg_stat_user_tables
WHERE seq_scan > 0
ORDER BY seq_tup_read DESC
LIMIT 25;
В верхней части таблиц будут как раз те самые операции, которые читали данные с диска. Если у таблицы больше 2000 записей, то такие операции должны производиться по индексу, а не с диска. Т.е. вы получите в первую очередь те запросы, которые вам потребуется оптимизировать.
Также вам следует посмотреть кеширование этих таблиц по представлению pg_statio_user_tables.
В этом вам помогут колонки heap_blks... и idx_blks...
9. Настраиваем память для PostgreSQL.
В зависимости от настроек сервера, настройки у вас будут примерно следующими:
effective_cache_size - 2/3 RAM
shared_buffers = RAM/4
temp_buffers = 256MB
work_mem = RAM/32
maintenance_work_mem = RAM/16
Но я рекомендую пользоваться специальными конфигураторами:
http://pgconfigurator.cybertec.at/ - продвинутый конфигуратор от Cybertec.
https://pgtune.leopard.in.ua/ - онлайн версия классического конфигуратора pgtune.
Эти инструменты помогут вам поставить нужные настройки за вас.
10. Настраиваем дисковую подсистему.
Если вам ничего больше ничего не помогло, то в крайнем случае вы можете выставить следующие настройки:
fsync=off
full_page_writes=off
synchronous_commit=off
Но в этом случае вы потеряете в надёжности хранения данных. Но если у вас PostgreSQL не является единственной системой по обработке данных и база асинхронно копируется в аналитические системы, то с такими настройками можно жить. Так как они снижают нагрузку на диск. Немного поясню по данным параметрам:
fsync – данные журнала принудительно сбрасываются на диск с кеша ОС.
full_page_write – 4КБ ОС и 8КБ Postgres.
synchronous_commit – транзакция завершается только когда данные фактически сброшены на диск.
checkpoint_completion_target – чем ближе к единице тем менее резкими будут скачки I/O при операциях checkpoint.
Ещё есть effective_io_concurrency – по количеству дисков и random_page_cost – отношение рандомного чтения к последовательному.
Впрямую на производительность не влияют, но могут существенно влиять на работу оптимизатора.
11. Настраиваем оптимизатор.
join_collapse_limit – сколько перестановок имеет смысл делать для поиска оптимального плана запроса. Интересный параметр. По умолчанию установлено 10, может имеет смысл повысить его в 10-20 раз.
default_statistics_target - число записей просматриваемых при сборе статистики по таблицам. Чем больше, тем тяжелее собрать статистику. Статистика нужна, к примеру для определения «плотности» данных.
online_analyze - включает немедленное обновление статистики
online_analyze.enable = on
online_analyze.table_type = "all"
geqo – включает генетическую оптимизацию запросов
enable_bitmapscan = on
enable_hashagg = on
enable_hashjoin = on
enable_indexscan = on
enable_indexonlyscan = on
enable_material = on
enable_mergejoin = on
enable_nestloop = on
enable_seqscan = on
enable_sort = on
enable_tidscan = on
12. Оптимизируем запросы.
Итак, вы нашли тяжёлые запросы, делаем по ним explain или analyze и первое на что вам следует обратить внимание - на следующие фразы:
- Seq Scan - значит, что запрос делается через последовательный перебор строк таблицы.
- Nested Loops - соединение с вложенными циклами.
Например, вас может насторожить следующий ответ базы:
Seq Scan ON test (cost=0.00..40.00 ROWS=20)
В ответе мы также видим, сколько строк будет обработано, а также стоимость первой строки..всех строк. Он считается достаточно оригинально, здесь стоит смотреть в относительном сравнении.
Также если Seq Scan по таблице, где rows более нескольких тысяч и при этом есть FILTER – в этом случае явно нужно посмотреть на поля в FILTER и найти подходящий индекс. Если не нашли – бинго, то одну из проблем вы решили.
Подробно описывать оптимизацию запросов я описывать не буду, это тема отдельной статьи.
Логика чтения плана запроса проста:
1) Смотрим на самый большой cost оператора
2) Это Seq Scan или nested loops?
3) Смотрим следующий по стоимости оператор
Оптимизация чаще всего заканчивается либо добавлением индекса, либо упрощением запроса (разбиением на части, использованием вложенных таблиц и т.п.), либо обновлением статистики, как это ни странно.
Для чтения планов рекомендую использовать следующий сервис:
https://tatiyants.com/pev
Что если проблема воспроизводится на проде?
В этом случае, вам надо воспользоваться параметром auto_explain. Он позволяет складировать ответ оптимизатора в одной папке. Включается следующим параметром:
session_preload_libraries = 'auto_explain'
auto_explain.log_min_duration = '3s‘
auto_explain.log_analyze = true
Теперь нам понадобится файлы вывести в красивом виде. В этом нам поможет pgBadger. Генерирует красивый html, но в настройках «можно утонуть».
https://github.com/darold/pgbadger
Вот так выглядит самая простая настройка:
pgbadger -j 4 -p '%t [%p]:[%l-1]' /var/log/postgresql/postgresql-9.6-main.log -o bad.html
На Prod auto_explain лучше не включать, или включать в крайнем случае и на короткое время. В случаях, если у вас нет просадки по ресурсам.
Стоит выделить наиболее часто встречающиеся ошибки:
- Поиск по базе с использованием LIKE ‘%spoon%’. В этом случае надо подумать о переносе поиска в ElasticSearch. Или использовать FULL TEXT SEARCH.
- Не внедрена система кэширования. Тогда стоит посмотреть на эту технологию: https://github.com/ohmu/pgmemcache. После скачивания и установки проделываем следующее:
shared_preload_libraries = ‘pgmemcache’
CREATE EXTENSION pgmemcache;
memcache_server_add('hostname:port'::TEXT)
Использование:
memcache_add(key::TEXT, value::TEXT)
newval = memcache_decr(key::TEXT)
memcache_delete(key::TEXT)
Если нужно кэширование внутри СУБД или временную таблицу в памяти. Но часто удобно использовать одну ORM или фреймворк имеет ограничения, или просто нужно оперативно заменить таблицу на inmemory KV хранилище.
- PostgreSQL используется в качестве OLAP. Самый простой вариант — быстро перенести данные в columnstore. https://github.com/citusdata/cstore_fdw
В данной статье я перечислил основные проблемы, с которыми сталкиваются разработчики при работе с базами данных. Если у вас есть интересный кейс или опыт, буду рад, если вы его пришлёте мне по электронной почте.